古典テスト理論の原則と応用(CTT)
このガイドは、心理的および教育的測定におけるフレームワークである古典テスト理論(CTT)の原則と実用的な応用の詳細な調査を提供します。構造化された旅を通して、それは起源、真のスコア、数学的なフレームワーク、仮説などの概念を掘り下げます。このガイドは、CTTの原則を効果的に理解および適用するための知識を備えており、評価の信頼性と妥当性を高めるための歴史的背景、技術的な詳細、実用的な戦略の融合を提供します。カタログ

起源
古典テスト理論(CTT)は19世紀後半に出現し、1930年代までに成熟し、現代の心理的および教育的測定の基礎を築きました。1950年代のグリックソンの仕事などの重要な貢献は、評価における信頼性と妥当性の重要性を強調し、数学的基盤を強化しました。1968年には、ロードとノウィックの画期的な出版物である心理テストスコアの統計理論がありました。これは、テストテイカーの特性や環境コンテキストなど、テストスコアとそれらに影響を与える要因の理解を高めました。CTTの原則は、標準化されたテストに広く適用されており、正確で公正な測定を目指しながら、バイアスやアイテムの改良などの課題に対処します。時間が経つにつれて、この理論は、実践と研究の動的な相互作用、現在の方法論を形成し、教育的および心理的評価のために維持することで進化しました。
適切な分数
心理的研究では、真のスコアの概念は、測定エラーの影響を受けない、正確に行動と認知を測定する必要があります。真のスコアは、ランダムエラーを最小限に抑えるために複数の評価を平均することによって決定されます。これらのエラーは、テスト中に欠陥のあるツール、状況的コンテキスト、または参加者の精神状態などの要因から生じる可能性があり、評価方法を改善するために使用されます。たとえば、適切に設計されたアンケートや信頼できるツールは、エラーを減らし、調査結果への信頼を高め、研究の質を向上させることができます。真のスコアには、教育者が単一のテストスコアではなく複数の評価に依存することにより、より公正な評価戦略を作成できるようにするなど、実際的な意味があります。真のスコアは、信頼性(測定の一貫性)と妥当性(測定されたものの精度)と絡み合っており、評価が一貫性と意味の両方のままであることを保証するためのツールを精製することの重要性を強調しています。
数学的枠組み
式x = t + eで表される数学的フレームワークは、観察されたスコア(x)、真スコア(t)、および測定誤差(e)の関係を説明しています。これに関連して、ランダムエラーはEに寄与しますが、系統的エラーはT内で説明されます。観測されたスコアは測定の結果を反映し、真のスコアは理想的なエラーのない値を表します。ランダムなエラーは予測不可能であり、環境条件やテストテイカーの変動などの要因から生じる可能性があり、多くの場合、繰り返しテストを緩和します。一方、体系的なエラーは一貫しており、測定ツールと方法論を慎重に調べる必要があります。このフレームワークは、評価の正確性、信頼性、および妥当性を確保するためにエラーを最小化することの重要性を強調しています。テスト環境の標準化やトレーニング評価者などの実用的な戦略は、測定の信頼性を高めます。x = t + eの意味を理解することは、責任を持ってデータを解釈し、誤判断を回避し、意思決定を確実にするために重要です。このフレームワークは、洞察と結果の質を向上させるための測定における精度の追求を示しています。
仮説
確立された方程式から、心理的評価における測定とエラーの複雑さを探る3つの相互に関連する仮説を導き出すことができます。
まず、n測定が行われると、平均誤差はゼロに近づく傾向があります。この観察により、真のスコアは、数学的にt = e(x)またはe(e)= 0として表現された平均観測スコアと一致すると結論付けることになります。この仮説は、信頼できる結果を達成するために十分に大きなサンプルサイズを持つことの重要性を強調しています。。サンプルが大きいほど、ランダム変動の影響が減少する傾向があり、真のスコアのより明確でより正確な表現を提供します。
第二に、ρ(t、e)= 0で示される真のスコアと測定エラーは独立して動作することを提案します。この独立性は、体系的なバイアスが真のスコアを揺さぶらないことを示唆するため、心理的評価の完全性を維持する必要があります。実際には、この独立を達成するには、厳密なテストプロトコルと、徹底的な信頼性と妥当性の評価を受けた検証済みの機器の利用が必要です。このような措置は、結果を歪める可能性のある潜在的な交絡変数の影響を軽減するのに役立ちます。
第三に、並列テストから生じるエラーはゼロであり、ρ(E1、E2)= 0として表されると主張します。ただし、並列テストを通じて同じ心理的特性を繰り返し評価することの実用性は、しばしば課題に直面しています。特性、被験者、テストの難易度、および分化の一貫性の必要性を含むさまざまな要因が、この努力を複雑にします。一般に、単一のテストがグループに管理されます。グループには、個々のエラーがランダムで正常に分布すると推定されます。この仮定は、効果的なデータ分析と解釈のための統計的方法の適用を促進するため、重要です。
グループ内の観測されたスコア、真のスコア、およびエラースコアの分散間の関係は、式SX = ST + SEを介して明確にすることができます。この式は主にランダムエラーを説明しますが、系統的エラーの分散は真のスコア分散に統合されます。理解を深めるにつれて、この方程式をSX = SV + Si + SEに改良することができます。SVは、測定目標に関連する分散を示し、SIはそれに依存しない分散を意味します。この視点は、すべての分散が測定誤差に起因するわけではないことを認めており、心理的構造の複雑さと多面的な自然行動を明らかにしています。
結論として、これらの仮説は、真のスコア、測定誤差、および心理測定におけるそれらの分散との間の複雑な相互作用を照らします。これらのダイナミクスを認識することは、評価方法の厳密さを強化するだけでなく、測定することを目的とした心理的構成要素の理解を高めます。
関連情報
ALLELCO LIMITED
もっと見る
クイックお問い合わせ
お問い合わせを送ってください、すぐに返信します。

IRQの基本:割り込み要求とは何ですか?それらはどのように機能しますか?
12/31/2024で公開されています
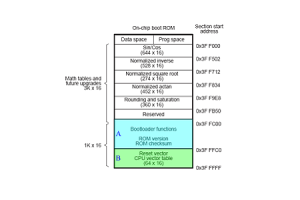
割り込みベクターテーブル:アーキテクチャ、管理、およびアプリケーション
12/31/2024で公開されています
ホットポスト
-

複雑な命令セットコンピューター:コンピューティングをどのように変更しましたか?
04/17/8000で公開されています 147713
-

USB-Cピンアウトと機能
04/17/2000で公開されています 111726
-
Xilinx Unified Simulation Primitivesの使用:FPGAの設計とシミュレーションの包括的なガイド
04/17/1600で公開されています 111322
-

電子機器における電源電圧: VCC、VDD、VEE、VSS、および GND の意味
04/17/0400で公開されています 83609
-

RJ45コネクタガイド:ピンアウト、配線、ケーブルタイプ、および使用
01/1/1970で公開されています 79260
-

現代の電気システムにおけるワイヤカラーコードの究極のガイド
電気システムの使用方法は、色だけではありません。各ワイヤーの色は特定の機能を示し、設置とメンテナンス中に電気コンポーネントを正しく識別して処理しやすくなります。これは、運用プロセスをスピードアップするだけでなく、間違いの可能性を減らし、ユーザーと技術者の両方を安全に保つのに役立ちます。この記事では、ワイヤーカラーコードの重要性、安全性と機能への影響、およびそれらを導くグローバル基準について説...01/1/1970で公開されています 66777
-

品質(Q)係数:方程式とアプリケーション
質の高い要因、または「Q」は、無線周波数(RF)を使用する電子システムでインダクタと共振器がどれだけうまく機能するかをチェックするときに重要です。「Q」は、回路がエネルギーの損失を最小限に抑え、システムが主要な周波数を中心に処理できる周波数の範囲にどの程度適切に影響するかを測定します。インダクタ、コンデンサ、および調整された回路を備えたシステムでは、より高い「Q」は、回路が特定の周波数に焦点...01/1/1970で公開されています 62946
-

パージバルブガイド:機能、症状、テスト、および最適なエンジン性能の交換
パージバルブは、大気に逃げる前に燃料蒸気を管理することで空気を清潔に保つのに役立つ車のシステムの重要な部分です。これは、汚染を減らすことで環境を支援するだけでなく、車の走行を改善し、燃料をより効率的に使用するようにします。この記事では、パージバルブの作業方法、タイプ、適切に機能しているかどうかを確認する方法など、パージバルブの詳細について説明します。 <h2 style=...01/1/1970で公開されています 62824
-

最大電力伝達定理でピーク性能を達成します
最大電力伝達定理は、バッテリーや発電機などのソースからのエネルギーが接続荷重にどのように流れるかを説明します。これは、負荷が最もパワーを受ける正確な条件を示しています。この記事では、定理の意味、DC回路とAC回路の両方でどのように機能するか、その背後にある証拠、その実生活のアプリケーション、およびその利点と短所について説明します。最後に、この原則がソーラーパネル、ラジオ、スピーカー、さらには...01/1/1970で公開されています 54028
-

A23バッテリー仕様と互換性
A23バッテリーは、高電圧の小さなシリンダー型のバッテリーです。23A、23AE、またはMN21とも呼ばれ、12ボルトで走行し、AAまたはAAAバッテリーよりもはるかに高くなっています。その特別なデザインにより、小さいながらも強力な電源が必要なガジェットに最適です。この記事では、A23バッテリーの機能、パフォーマンス、および使用について説明します。さまざまなブランドやその他...01/1/1970で公開されています 51989
ホットパーツ番号
-

SP491EEP-L
MaxLinear, Inc.
IC TRANSCEIVER FULL 1/1 14DIP
LT1952EGN-1#PBF
Analog Devices Inc.
IC REG CTRLR FWRD CONV 16SSOP
SN74CBT3383DGVR
Texas Instruments
IC BUS FET EXCH SW 5X2:2 24TVSOP
FSB50250UD
onsemi
MOD SPM 500V 1.1A SPM23-HD
5.0SMDJ70CA
Littelfuse Inc.
TVS DIODE 70VWM 113VC DO214AB
BAT54-HE3-08
Vishay General Semiconductor - Diodes Division
DIODE SCHOTTKY 30V 200MA SOT23-3
FDS8934A
onsemi
MOSFET 2P-CH 20V 4A 8SOIC
VE-243-EW
Vicor Corporation
DC DC CONVERTER 24V 100W
MT29F1G08ABAEAH4:E
Micron Technology Inc.
IC FLASH 1GBIT PARALLEL 63VFBGA
100324QC
Fairchild Semiconductor
IC TRANSLATOR UNIDIR 28PLCC
UC2525BN
Texas Instruments
IC REG CTRLR MULT TOPOLOGY 16DIP
SN74LS109AN
Texas Instruments
IC FF JK TYPE DUAL 1BIT 16DIP
TPS3307-25D
Texas Instruments
IC SUPERVISOR 3 CHANNEL 8SOIC
F1892CCD1600
Sensata-Crydom
DIODE MODULE 1.6KV 90A
PKB4418PIOANB
Flex Power Modules
DC DC CONVERTER 1.5V 45W
MC74VHCT132ADTRG
onsemi
IC GATE NAND SCHMITT 4CH 14TSSOP
SZESD9101P2T5G
onsemi
TVS DIODE 5VWM 7VC SOD923
APT17F120J
Microchip Technology
MOSFET N-CH 1200V 18A ISOTOP -

T495X477K010ATE100
KEMET
CAP TANT 470UF 10% 10V 2917
SMBJ12CA
Taiwan Semiconductor Corporation
TVS DIODE 12VWM 19.9VC DO214AA
ADG419BRMZ-REEL7
Analog Devices Inc.
IC SWITCH SPDT X 1 35OHM 8MSOP
18085C473JAT2A
KYOCERA AVX
CAP CER 0.047UF 50V X7R 1808
593D107X9010D2TE3
Vishay Sprague
CAP TANT 100UF 10% 10V 2917
STM32L083RZT6
STMicroelectronics
IC MCU 32BIT 192KB FLASH 64LQFP
S-80958CNMC-G9UT2G
ABLIC Inc.
IC SUPERVISOR 1 CHANNEL SOT23-5
SN74LV4053ANSR
Texas Instruments
IC SWITCH SPDT X 3 75OHM 16SO
RC0201JR-0710KL
YAGEO
RES 10K OHM 5% 1/20W 0201
RD6.2MW-T1B-AT
Renesas
RD6.2MW-T1B-AT - ZENER DIODES 20
C2012X7R1E105K125AB
TDK Corporation
CAP CER 1UF 25V X7R 0805
SN74HC4060PWR
Texas Instruments
IC BINARY COUNTER 14BIT 16TSSOP
R2A30428BM#W0
Renesas Electronics America Inc
MOTION CONTROL ELECTRONIC
DF2B7SL,L3F
Toshiba Semiconductor and Storage
TVS DIODE 5.3VWM 16VC SL2
AS6C4016A-45BIN
Alliance Memory, Inc.
IC SRAM 4MBIT PARALLEL 48VFBGA
RT0805DRE0715RL
YAGEO
RES SMD 15 OHM 0.5% 1/8W 0805
TPA6011A4PWPR
Texas Instruments
IC AMP CLASS AB STER 3W 24HTSSOP
PALR-08VF
JST Sales America Inc.
CONN PLUG HSG 8POS 2.00MM -

NDS6S2405C
Murata Power Solutions Inc.
DC DC CONVERTER 5V 6W
HCPL-0710
Broadcom Limited
OPTOISO 3.75KV PUSH PULL 8SO
ADS4122IRGZR
Texas Instruments
IC ADC 12BIT PIPELINED 48VQFN
FAR-D6JH-2G1325-B1YZ-Z
Taiyo Yuden
RF DUPLEXER 9SMD NO LEAD
TIP32C
onsemi
TRANS PNP 100V 3A TO220
NP50P06KDG-E1-AY
Renesas Electronics America Inc
MOSFET P-CH 60V 50A TO263
06031C562K4Z2A
KYOCERA AVX
CAP CER 5600PF 100V X7R 0603
OPA27GU/2K5
Texas Instruments
IC OPAMP GP 1 CIRCUIT 8SOIC
DAC900U
Burr Brown
IC DAC 10BIT A-OUT 28SOIC
LT1004CDR-2-5
Texas Instruments
IC VREF SHUNT 0.8% 8SOIC
NTB75N03L09T4
onsemi
MOSFET N-CH 30V 75A D2PAK
MBRF10100CT-JT
Diodes Incorporated
DIODE ARRAY 100V 5A ITO220AB
XC5VLX155T-2FFG1136C
AMD
IC FPGA 640 I/O 1136FCBGA
AT25640B-SSHL-T
Microchip Technology
IC EEPROM 64KBIT SPI 20MHZ 8SOIC
MAX14736EWL+T
Analog Devices Inc./Maxim Integrated
IC RF RECEIVER 9WLP
045202.5MRL
Littelfuse Inc.
FUSE BRD MNT 2.5A 125VAC/VDC SMD
IRLI520GPBF
Vishay Siliconix
MOSFET N-CH 100V 7.2A TO220-3
P1014NSE5DFA
NXP USA Inc.
IC MPU Q OR IQ 800MHZ 425TEBGA1